diglloydTools™
diglloydTools™










Why More CPU Cores Often Run no Faster, and Sometimes Slower than Fewer CPU Cores
Related: 2013 Mac Pro, 2017 iMac 5K, 4K and 5K display, computer display, CPU cores, diglloydTools, iMac, iMac 5K, iMac Pro, Mac Pro, memory, performance, scalability
Need help deciding on a Mac? Lloyd offers one-on-one consulting on choosing the best Mac and its best configuration, backup protocol, displays, storage and RAID, etc.
This post is directly relevant to the forthcoming 2017 iMac Pro, which has CPU options of 8/10/14/18 CPU cores, with 14 and 18 CPU cores being unprecedented for Apple Macs (12 was the previous max).
The threshold of noticing any difference in performance is around 10%, so in theory 18 CPU cores sounds terrific: 18 versus 8 sounds like no contest. Yet more CPU cores can be slower or offer only minor improvement—it all depends on the workload. Three test examples follow, which illustrate that idea.
Only with very specific multithreading-friendly workloads do 10/14/18 CPU cores get more done significantly faster than 8 or 10 cores. That assumes excellent software implementation with a scalable algorithm. With most workloads, the differences are modest even between 4 and 8-core CPUs.
The foregoing is why a 2017 iMac 5K can often be a superior value for many computing tasks: it can run all 4 of its cores at 4.2 GHz whereas the 8/10/14/18 CPU core iMac Pro Intel Xeon W CPUs must drop the clock speed dramatically as more CPU cores are used, reducing the benefits of each additional CPU core. At the same time, more cores all contend with each other for scarce resources and must in essence “take turns”.
On the flip side, the 2017 iMac 5K has only 2-channel memory vs 4-channel memory on the iMac Pro, so with workloads that are memory intensive, the 2017 iMac 5K cannot use its 4 CPU cores effectively, being throttled by having CPU cores wait for relatively slow main memory.
Many factors contribute to scalability. Good scalability means that twice the CPU cores would get the job done in about half the time. That can be true for 2/4/6 core machines for well written software, but going beyond 6 CPU cores, many factors conspire to make further improvements incremental.
- As more CPU cores are used, Intel Turbo Boost drops the clock speed down to the base clock speed—each CPU core slows down as more are used. See the chart of turbo boost clock speeds for Intel Xeon E series (as this was written, data was not available for the Intel Xeon W processors).
- Contention for on-chip cache memory and contention for main memory—CPU cores are forced to wait on molasses-slow main memory (far slower than CPU registers and on-chip memory caches).
- Contention for shared application data structures (“thread safety”)—CPU cores are forced to queue up to access a necessary resource. The must “take turns” and thus go idle while waiting.
- Inappropriate algorithm selection for many CPU cores and/or poor multi-threading implementation. This is a software engineering problem. Some workloads can only be done in a sequential series of steps; this is called serialization and it precludes using many CPU cores (or even two). The workload can be a series of single-threaded and multi-threaded tasks. How much more CPUs helps depends heavily on whether the task can be split up for each CPU core to handle simultaneously. This is Hard To Do in software development, even if the task is amenable to it, and attempts to parallelize often lead to difficult to track down sporadic bugs. Few software engineers have the skills to write correct multi-threaded code.
Examples — scalability
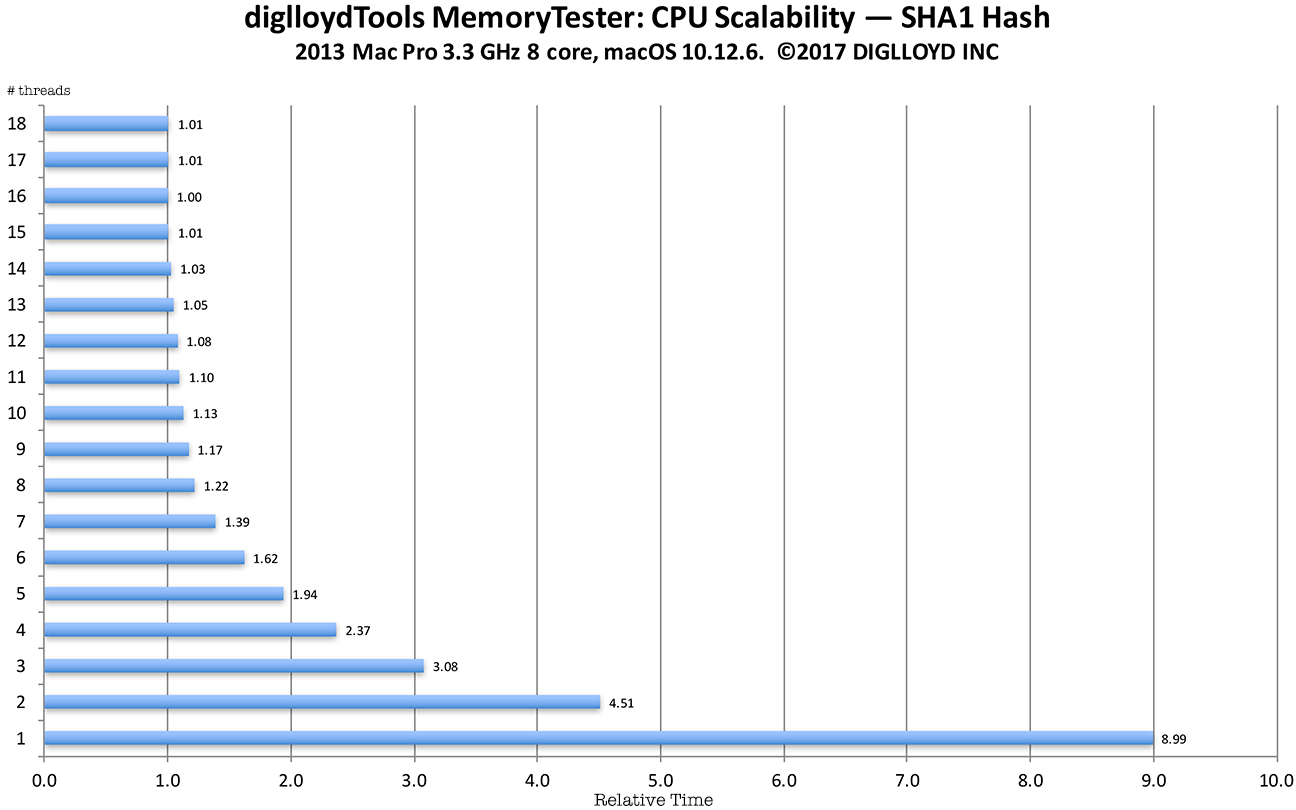
Example : scalability of SHA1 hash
The example below uses data from the compute command of diglloydTools MemoryTester using the 2013 Mac Pro with a 3.3 GHz 8-core CPU.
The test runs the SHA1 cryptographic hash, used by diglloydTools IntegrityChecker for file integrity checking.
The SHA1 algorithm has moderate memory access and a lot of integer computation. It is multithreading-friendly in that it does a lot of computation relative to its memory access. Different CPU threads can run independently (simultaneously) while hashing different chunks of data; the main contention points are taking a task off a queue and putting a result onto a results queue. That is a relatively easy coding challenge to tackle, so that memory access becomes the limiting factor—but since there is a lot of computation relative to memory access, even 8 CPU cores scales near perfectly. That is unless disk I/O is involved as with using diglloydTools IntegrityChecker in which case performance is usually limited to how fast the data can be read off the disk. Here in this example, there is no disk I/O whatsoever so it is as good as it gets.
Notes on the graph below
- A single thread (relative time 8.99) on the 8-core CPU takes 7.4X longer to complete the computation than 8 threads( 8.99 / 1.22= 7.4).
- Virtual CPU cores aka hyperthreading helps up to 16 threads — all the virtual cores, then begins to degrade performance.
- Using virtual CPU cores (hyperthreading) yields a 22% performance improvement (8 threads relative time 1.22 vs 16 threads relative time 1.00).
- This test is highly scalable with threads up to the number of real CPU cores: 6 threads takes 1.328 times as long (1.62/1.22 = 1.328) which is the theoretical maximum of 1.333 (8/6 = 1.333). For real-world work, such scalability is unusual. However, note that 4 threads takes 1.94X as long as 8 threads (2.37 vs 1.22).
Given the foregoing theoretical realities and this actual example, it’s not at all clear how beneficial 10/14/18 cores will be. Clearly the use of 8 CPU cores on a highly scalable workload is of benefit, but with more memory access and/or more CPU cores, the scalability will decline.
Time are normalized; a time of 1.0 is the minimum and fastest. Up to 18 threads were used, corresponding to the 18 virtual CPU cores of the 8-core CPU.
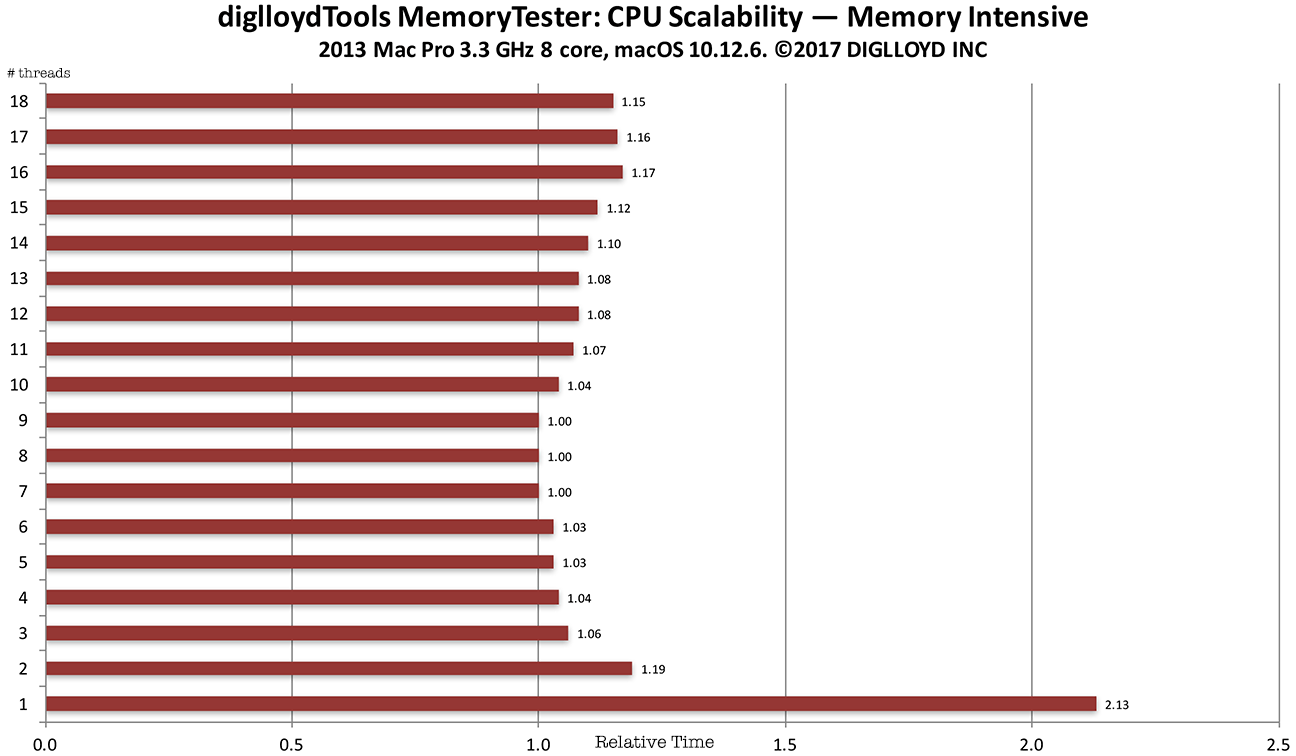
Example : scalability of memory intensive workload
In the graph below, the workload consists of constant memory access—a worst case scenario. Scalability is poor, with the 4-channel memory of the 2013 Mac Pro maxed out with 3 CPU cores. The about 4% improvement seen with 7 or 8 CPU cores versus 3 CPU cores is due to overlapping instruction execution but it’s hardly a big win.
Example : scalability of pure CPU workload
In the graph below, the workload involves no memory access at all, thus showing the best possible case. Scalability is good up to the number of real CPU cores: 4 CPU cores takes 1.955X times as long (2.19 / 1.12 = 1.955), with 2.0X times as long being perfect scalability. Of course, macOS runs background tasks, so we can call this perfect scalability since there is always some background activity that cannot be eliminated (so 8 CPU cores are not realy all available).
The use of hyperthreading (virtual CPU cores) has value, with 16 threads about 12% faster than 8 threads on this 8-core CPU.