diglloydTools™
diglloydTools™










OS X File System Hang Bug
UPDATE June 2014: As far as I can determine, this bug has been fixed in OS X 10.9.3. While my bug report at Apple has not been updated to reflect the fix, I have yet to see the issue resurface in 10.9.3.
Update December 2014: Apple still has not fixed the bug.
However, Apple developer support tells me that the bug is NOT fixed in 10.9.x (but to be fixed in 10.10 Yosemite), so the workaround of disabling file system journaling is still a wise precaution when testing drives.
I spent all weekend tracking down a hang bug in the OS X Mavericks file system (the bug is new to Mavericks, the most bug-ridden OS X version ever released).
It is a severe bug: a reboot does not cure it, the file system always verifies as good, but any attempt to access the file causes a complete OS X lockup, and the only fix is to erase the volume. A nasty little bugger.
This particular bug involves the file system, but only Mac OS Extended (does not affect ExFAT). I reported it a few months ago, and it is 100% reproducible by myself on several different machines with different hardware and by independent 3rd parties, yet the response in Apple Bug Reporter has been a “cannot reproduce” so lacking in details as to make one skeptical that it was actually even tested at all.
For programming nerds, it involves FSAllocateFork(), or in POSIX API terms, fcntl(fd, F_PREALLOCATE, ¶ms). It requires use of software RAID-0 (Disk Utility or SoftRAID, doesn't matter) or concatenated RAID, occurs with SSDs or hard drives, with Thunderbolt or eSATA, and on a laptop or desktop. It requires a large file, but the size varies and the bug can be triggered below certain threshold in other ways too.
So my weekend was spent in a fruitless effort to find a workaround—none.
But I did determine that the bug occurs not just in Carbon APIs but also in low-level POSIX APIs (rather scary to see it at that level), so it runs deep and it’s just one more core rot introduced by Mavericks.
I have now submitted source code along with a binary program showing the problem, which is again confirmed by multiple 3rd parties. I wonder if “cannot reproduce” will be the response yet again from Apple. It’s incredibly frustrating to see the long latency in response time as well as the apparent inattention to detail. I have the distinct impression of little interest or inclination to investigate.
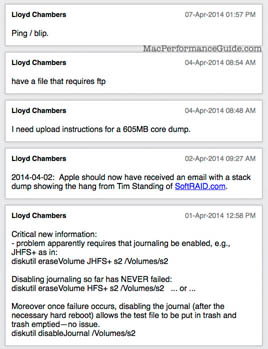
Update April 1st
(It’s April 1st but this is no joke).
A thank you to the OWC staff for reproducing and confirming.
Also, Tim Standing of SoftRAID.com was able to help by reproducing the bug and getting a stack dump to submit to Apple.
UPDATE: staffing at Apple is apparently minimal. A request for the core dump upload instructions going unanswered, and my bug updates have not been addressed for three days.
The key factor appears to be journaled HFS+ file system. It will be nice if Apple fixes it (bug #15821723 updated), but at least there is a workaround that does not require a complete volume erase.
Disabling journaling not only prevents the issue from occurring (at least I can no longer reproduce it with journaling off), but it allows a volume with a problem test file to be removed (put into trash, empty trash).
Disabling HFS journaling
In Terminal, use the commands in red. It is easily reversible. Journaling is strongly advised for most all uses, so disable it temporarily only.
# Disable HFS journaling on volume 'Scratch' diglloyd:DIGLLOYD lloyd$ diskutil disableJournal Scratch Journaling has been disabled for volume Scratch on disk14 ... remove the file, e.g., put into trash and empty trash ... # Enable HFS journaling on volume 'Scratch' diglloyd:DIGLLOYD lloyd$ diskutil enableJournal Scratch Journaling has been enabled for volume Scratch on disk14
Apple’s (non) Response
Update May 8: a response from Apple. No details on when the bug will be fixed.
We’ve managed to reproduce the problem and we understand what is going wrong. Apologies for the delay in responding.