diglloydTools™
diglloydTools™





When a Hard Drive Fails: Rebuilding a RAID-5 in SoftRAID
One bad hard drive causes very confusing failures
I’ve been having random drive blips that would take down my RAID. The same drive was always involved, determined by its ID in SoftRAID. Sometimes things would run fine for hours, and sometimes (yesterday) I could provoke the error in 30 seconds just by doing Finder copy or diglloydTools IntegrityChecker verify. I was beginning to worry that if it was my 2017 iMac 5K, but that was baseless as I was able to reproduce the issue on the 2016 MacBook Pro.
I spent the better part of my day tracking down the problem to this one drive. I tried 3 different cables, two different Macs, two different OWC Thunderbay 4 enclosures (and both ports on the enclosure), macOS 10.13 and 10.14, daisy-chained and alone, verified the file system—even a different power outlet in a different room.
In all cases, the same drive was always noted as the culprit that failed to complete an I/O, somehow having the effect of disconnecting all drives in the enclosure. This is a little strange, and so I hope it is just that drive. Still, when I removed it and tried to provoke a problem, no problem.
Replacing a failed drive in a RAID-5 or RAID-4
RAID-5 (or RAID-4) both provide fault tolerance by storing parity information with which the actual data can be reconstructed. With the loss of one drive, the RAID-5 in effect degrades to a RAID-0. So if one drive fails, nothing is lost and you can keep working.
With perhaps fifty (50 failures over the past two days (the one bad drive going AWOL causing it all), I watched SoftRAID perform flawlessly with its smart rebuild capability, which kept rebuilds to a minute or so. But this bad drive just did not play nice, so I physically removed it.
Bringing the RAID-5 back up to full fault tolerance means replacing the failed drive. The following screen shots show the process.
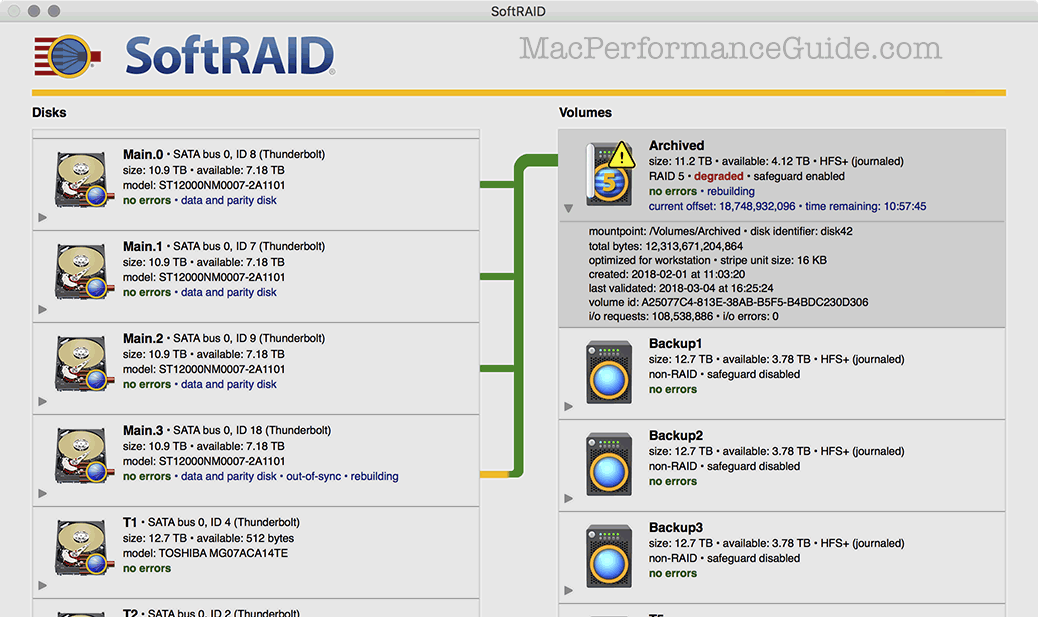
The degraded RAID-5
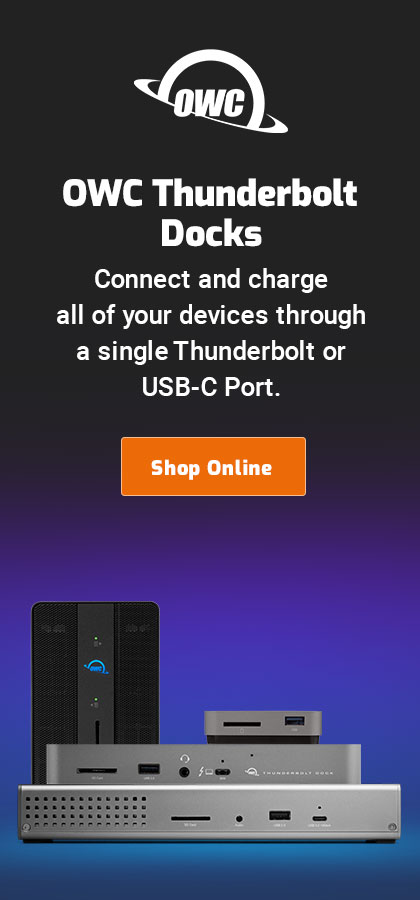
Here, “degraded” means that one of the drives has gone away and the RAID-5 is now a RAID-0 stripe—another failure and everything is toast, but that’s what backups are for. In this case I physically hot-removed the problem drive, given all the issues it was causing as discussed above.
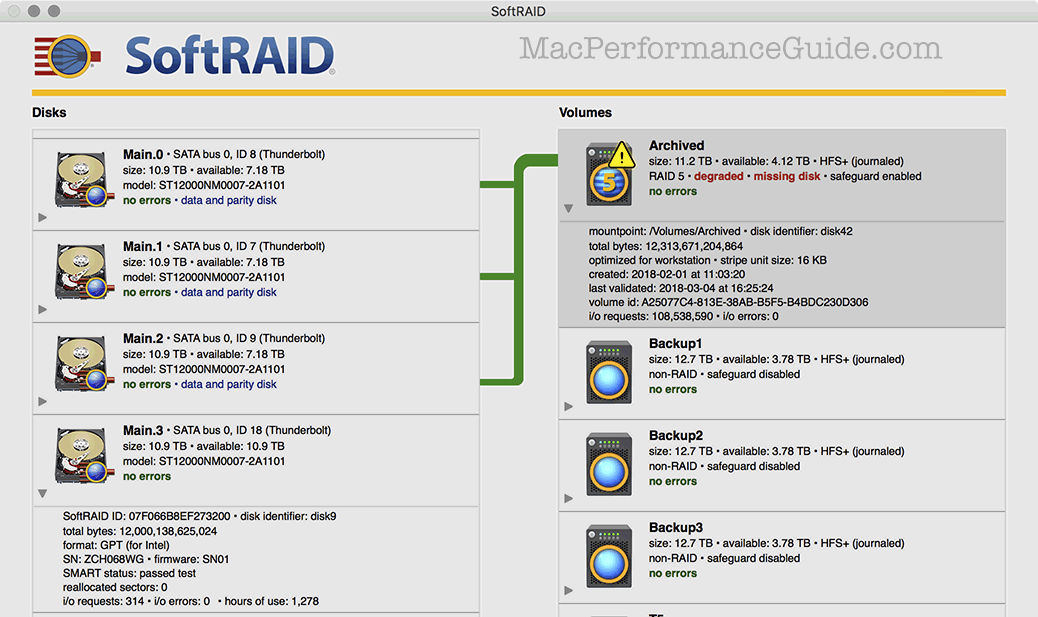
Adding a replacement drive
The bad drive being physically removed, I bolted a replacement into a drive sled and hot-inserted it into the OWC Thunderbay 4. I then chose to tell SoftRAID to add this disk to the RAID-5.
A confirmation dialog confirms the choice above:
With the replacement drive in place, SoftRAID goes to work rebuilding the RAID-5 for full fault tolerance. With 12TB drives (11.2 TiB), this takes a while (about 11 hours), since the entire capacity has to be read of each drive, in order to generate the appropriate data to go on the replacement. There is no downtime however—the volumes can keep being used, albeit with a performance loss because of the rebuild process but totally usable.