
 diglloydTools™
diglloydTools™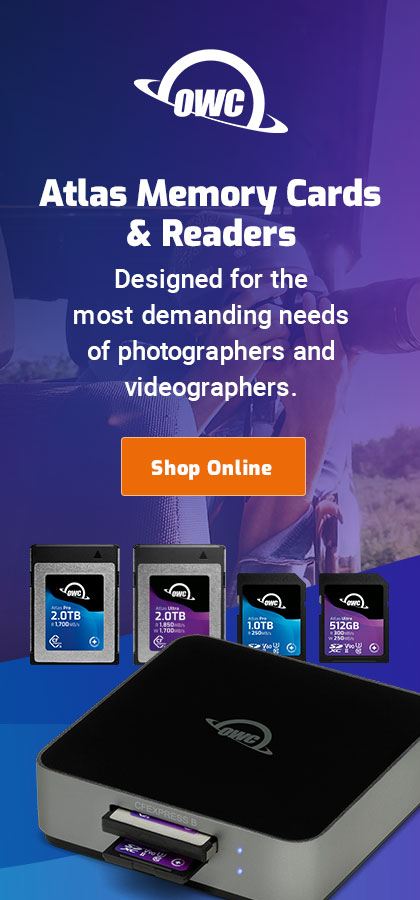












Even ”Enterprise Grade” Drives Fail
Related: diglloydTools, hard drive, HGST, Other World Computing, RAID, SoftRAID
It’s called Mean Time Between Failure because it’s awfully mean of an enterprise-grade hard drive to fail in less than 13 months. Happy New Year to you too, HE8.
Seriously, “mean” is average, as in Mean (average) Time Between Failure (MTBF). Drives fail, and while an enterprise drive might last 5 years, it might like to fail in one year, as shown below. As in mean time to failure—an average.
I’ve been running the HGST Ultrastar He8 8TB hard drives in a 4-way RAID-0 stripe for just over a year—see my in-depth review of the HGST 8TB Ultrastar He8 hard drive. I’ve been very pleased with the performance and low noise level.
A drive failure is luck of the (mean) draw. VERY bad luck in this case, given the remarkable 0.00% annualized failure rate for HGST 8TB drives stated at BackBlaze.com (exact same model number). The longer term failure rate (see link) is 2.7% for the HGST He8 HUH728080ALE600 across 26953 drive days: 2 failures total but it’s unclear how many drives.

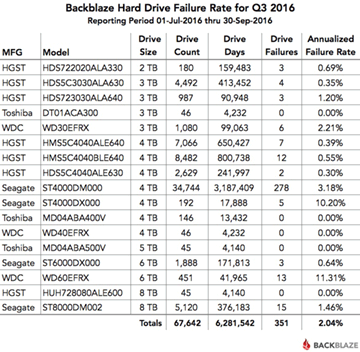
A big plus of SoftRAID is its advance warning of impending drive failure, as shown below. See the OWC blog post on drive failure, with Tim Standing’s video presentation as well as BackBlaze hard drive stats for Q3 2016. There is a longer version of Tim Standing’s presentation available and see also all the other presentations from the Mac Sys Admin 2016 conference.
OWC is unique in that if you get a failing drive like this on a Thunderbay RAID, we’ll RMA it and replace it.
Even with this awesome warranty policy, MPG recommends a cold spare, because shipping takes time. In my case I do not keep a cold spare, but I do have 4 “warm” spares each of which are single-drive backups, so I will just scavenge one of them.
Continues below...
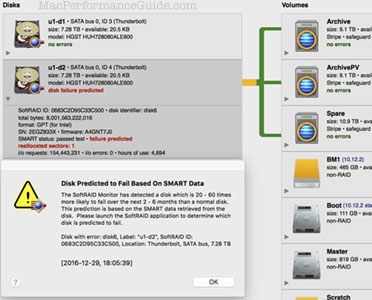
Checking drives before putting into “production”
SoftRAID has a superb 'certify' command which is excellent, and MPG recommends using it.
However, diglloydTools DiskTester fill-volume command can test 99% of the drive and graph the behavior, as shown below, where 5 samples were tested simultaneously, and then graphed together to verify consistent performance—important for RAID setups.
Over the years I have found that aberrant performance behaviors (obvious in a graph) are often an excellent predictor of flaky drives. The test-reliability command is good too, with the major benefit of being able to operate on in-use drives—no need to take a system down for days to certify (which means having to completely wipe) the drives.
Verifying data after moving/copying it

Steps in doing a major data transfer/conversion/fix:
- Bring all hashes up to date with diglloydTools IntegrityChecker using the update command.
- After cloning or copying over the data from the backup or old volume to the new, run IntegrityChecker verify to verify 100% bit-for-bit data integrity.
Below, the summary output for the two volumes I had to redo, and . The one missing file is just some temp file, so it is of no importance. Content did not change in any files totaling about 6.5TB of data.
====================================================== ic verify ArchivePV 2016-12-30 at 09:15:40 ====================================================== # Files with stored hash: 104968 # Files missing: 1 ================== # Files hashed: 104967 # Files without hashes: 0 # Files whose size has changed: 0 # Files whose date changed: 0 # Empty files: 1 # Files whose content changed (same size): 0 # Suspicious files: 0 ... ====================================================== ic verify Archive (summary) 2016-12-30 at 11:29:30 ====================================================== # Files with stored hash: 197325 # Files missing: 1 # Files hashed: 197324 # Files without hashes: 0 # Files whose size has changed: 0 # Files whose date changed: 26 # Empty files: 1 # Files whose content changed (same size): 0 # Suspicious files: 0
