
 diglloydTools™
diglloydTools™


$220 SAVE $130 = 37.0% Western Digital 16.0TB Western Digital Ultrastar DC HC550 3.5-in… in Storage: Hard Drives
|

|

|

|

|

|

|

|

|

|
2014 Update: Adobe Photoshop CC Scalability
Related: bandwidth, CPU cores, Mac Pro, Macs, memory, memory bandwidth, Photoshop
See the diglloydSpeed1 benchmark.
Data for this graph was measured in January 2014 using the latest Adobe Photoshop Creative Cloud on a 12-core 3.33 GHz 2010 Mac Pro.
CPU cores were disabled in software in order to obtain this data. Hyperthreading was left enabled (tested, it made no meaningful difference either way).
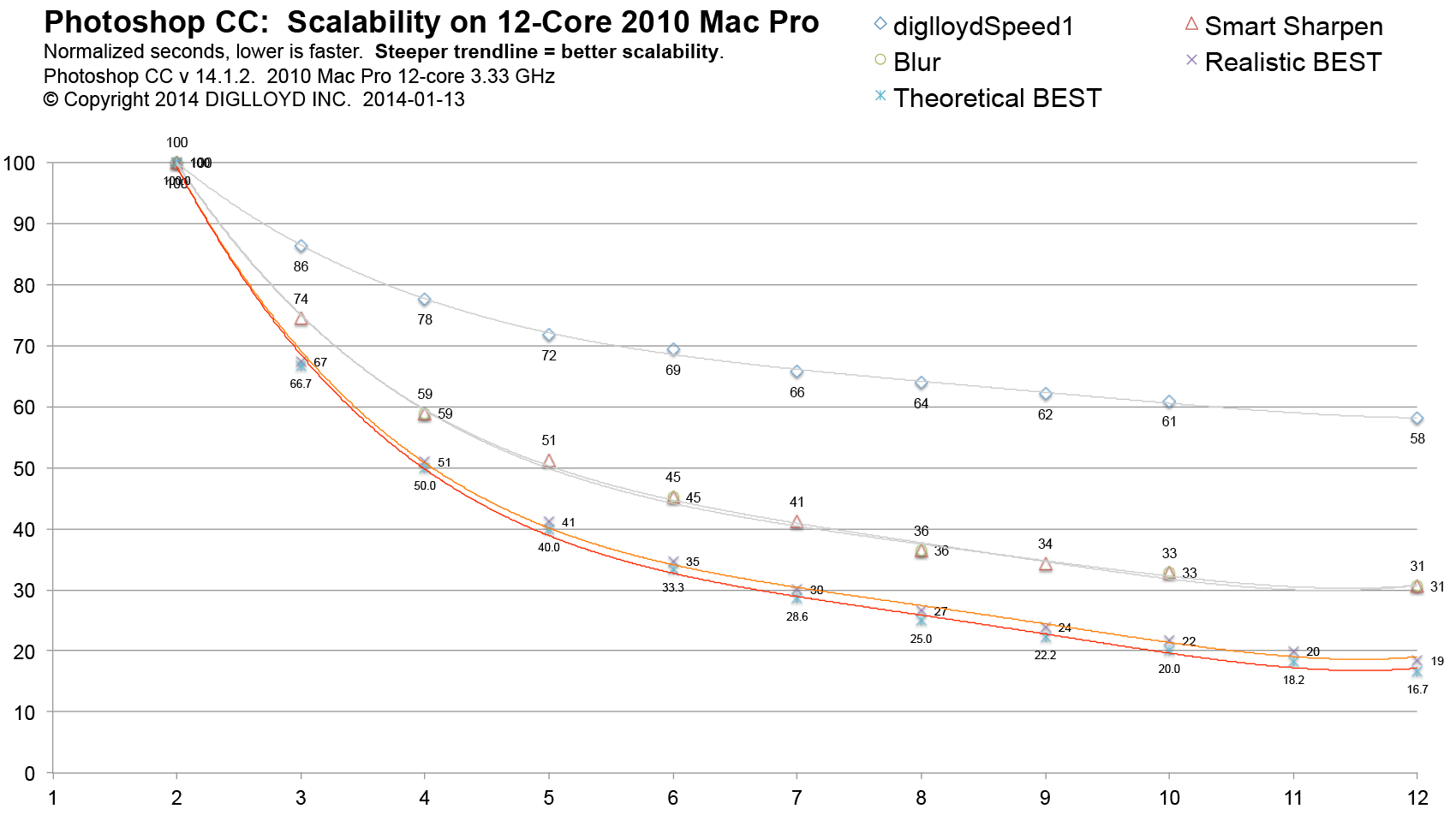
The graph below neatly captures the scalability behavior of Adobe Photoshop CC.
How much faster does a 6/8/10/12 core CPU run than a 4-core CPU?
The asymptotic pattern is obvious at a glance—rapidly diminishing returns beyond 6 cores, the same effect seen over years. It’s “game over” at 8 cores.
The behavior could be explained by memory bandwidth limitation, synchronization overhead and general software inefficiencies (in design). Of these, bandwidth is a likely culprit, a theory that the 2013 Mac Pro might help prove or disprove, since it has much higher memory bandwidth.
While other functions might scale better, the results for Photoshop CC are unequivocally disappointing for anyone investing in those extra cores. That additional CPU usage seen in Activity Monitor is apparently mostly overhead busy work (thread contention), not useful computation. Whatever the reason, it’s clear that 12 cores offers little benefit over 6 or 8 cores on the 2010 Mac Pro. Again, the 2013 Mac Pro might fare somewhat better if memory bandwidth is responsible.
Some applications are written to be scale well and fare much better than Photoshop CC. An existence proof is the awesome scalability of PhotoZoom Pro 4.
A choice of CPU should consider all aspects of the workflow.

Notes
- The general mix of functions in diglloydSpeed1 scales very badly; a two-core Mac Pro takes only 1.7X as long as a 12-core Mac Pro! A 4-core Mac Pro takes only 1.33X as long as a 12-core.
- The SmartSharpen function scales much better. Still, 4 cores takes only 1.9X as long as a 12 cores, and 6 cores takes only 1.48X as long as 12-core.
- For Smart Sharpen (more scalable than diglloydSpeed1), a 6-core system takes 1.13X as long as an 8-core system—noticeable if paying close attention.
Actual vs best possible
This graph normalizes the results for two cores to a value of 100 for each test, while also adding a theoretical best (perfect scalability) and a realistic real world expectation: 10% loss of efficiency with 12 cores versus 2 cores.
The general mix of operations (diglloydSpeed1) can be seen to offer very limited scalability, whereas the Smart Sharpen and Blur results take about 1.6X as long to run as a realistic real world expectation. That difference amounts to 7.5 cores versus 12 (12 / 1.6), which is where the preceding graph goes very close to asymptotic.
Seagate 22TB IronWolf Pro 7200 rpm SATA III 3.5" Internal NAS HDD (CMR)
SAVE $100
